TOC
Idea
When not coding and building IoT project I spend time working on a personal project or building an aircraft, and to be more specific a South African designed Sling TSi.
The design of the aircraft is widely regarded in Light Aircraft circles as being one of the best 4 seat aircraft out there for the home builder and one of the main reason I picked the design, now I know what your thinking have I opened the wrong blog post here what’s all this Airplane speak…
Well there is an issue with the Factory shipping the kits around the world and that is that they struggle to get the trained staff due to Covid issues and thus kits are being shipped with incorrect parts or 2 left parts when there should be a left and a right for example. My idea is that I have this awesome Percept device I have been loaned from Microsoft to write some blog posts and have a play with and I got to thinking could I train it to recognise the parts and show the tagged name of the part so that an untrained shipping agent in the factory could us it to make sure the kits has all the correct parts?
Let have a play and see shall we…
Where do we start?
We start in the Azure Portal and more specifically the Azure Percept Studio where we can access the Vision Blade of the Percept Device. In here click the ADD button at the top to add a new Vision Project.
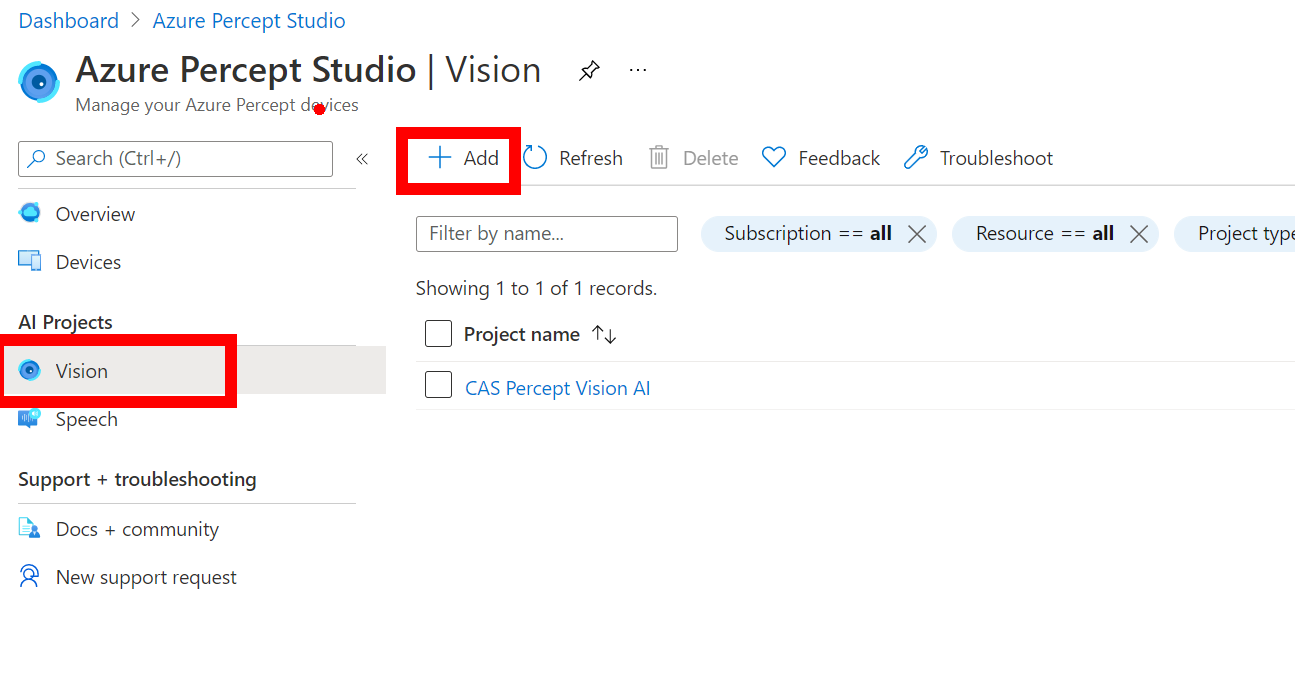
In the new blade you can fill in the boxes by giving the new Vision Model a name and a nice description (For when you or a college comes back in a few months and wonder what this is!), then you can make sure you have Object Detection selected and Accurancy and you can then click Create at the bottom of the page.
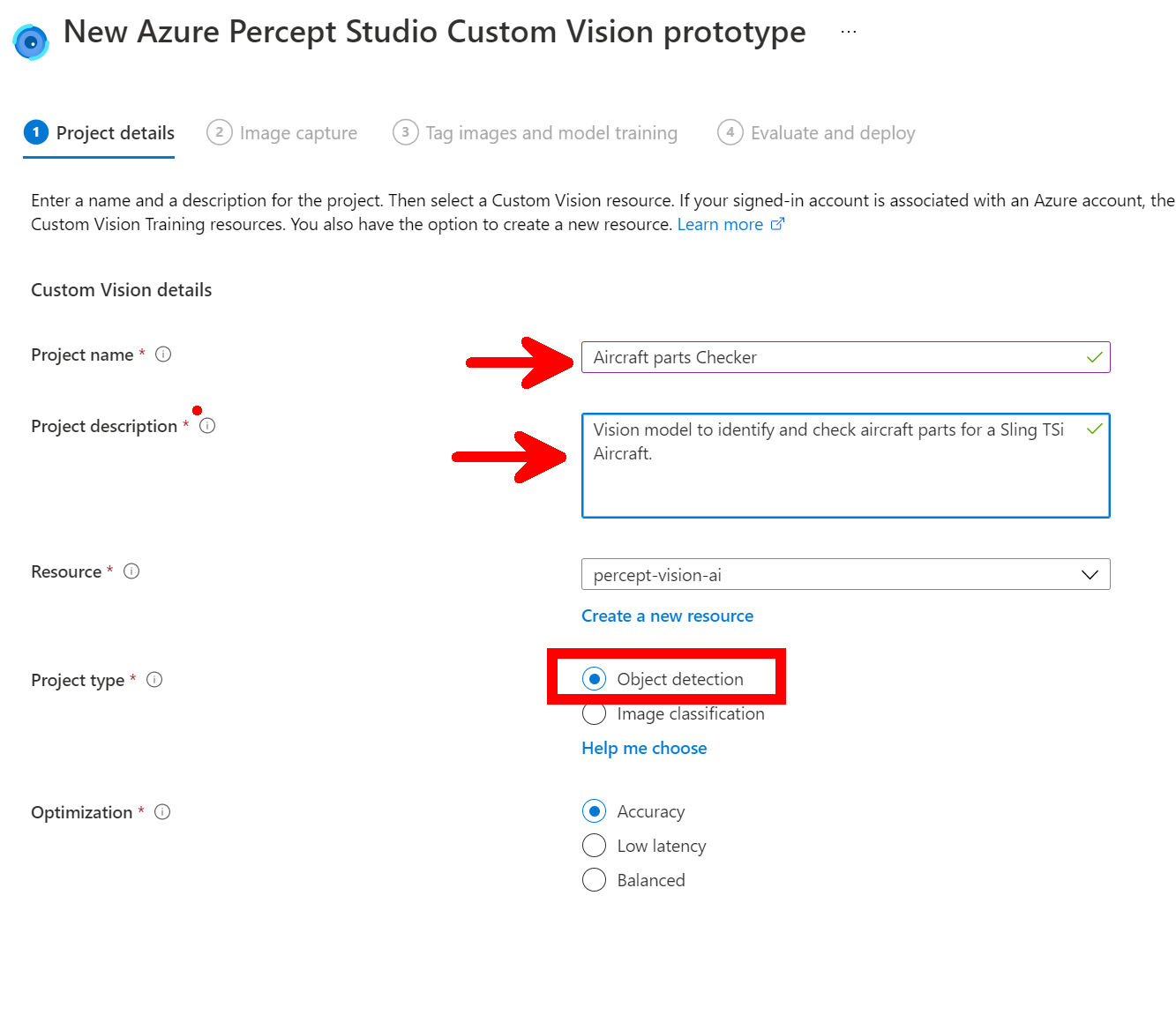
Image Capture
Next we move onto the Image capture that is then used to train the model with our first parts, so make sure you have the correct device selected and tick the Automatic image capture checkbox and the drop-down lists will appear where you can select the setting needed. As this is just the first images of the first component I want to capture to test everything is working I have set mine to be 1 Frame every 5 seconds and Target to 25 this means that the Percept will take a photo every 5 seconds until it has taken 25 photo’s. These images will then all be loaded into the AI model ready to be tagged and trained.
Small issue is that you don't really know when the images are being taken and when it has started... So if you click the `View Device Stream` just above the Automatic Image Capture you will see what the Percept-EYE can see and watch as the images are taken.
The alternative if you have enough hands is to NOT tick the Automatic Image Capture in which case the button bottom left will say Take Photo and this will take a single photo. However I find I need more hands than I have, but this would be good if the Percept is right next to you on your desk but not so good it’s on the factory floor.
Custom Vision
Now we have the images and yes I know there is not really any feedback with this method of training it would be nice if the Stream Video in the browser had a border that flashed up with a colour or something when an Image was captured so you knew what was happening but hey ho with work with what we have.
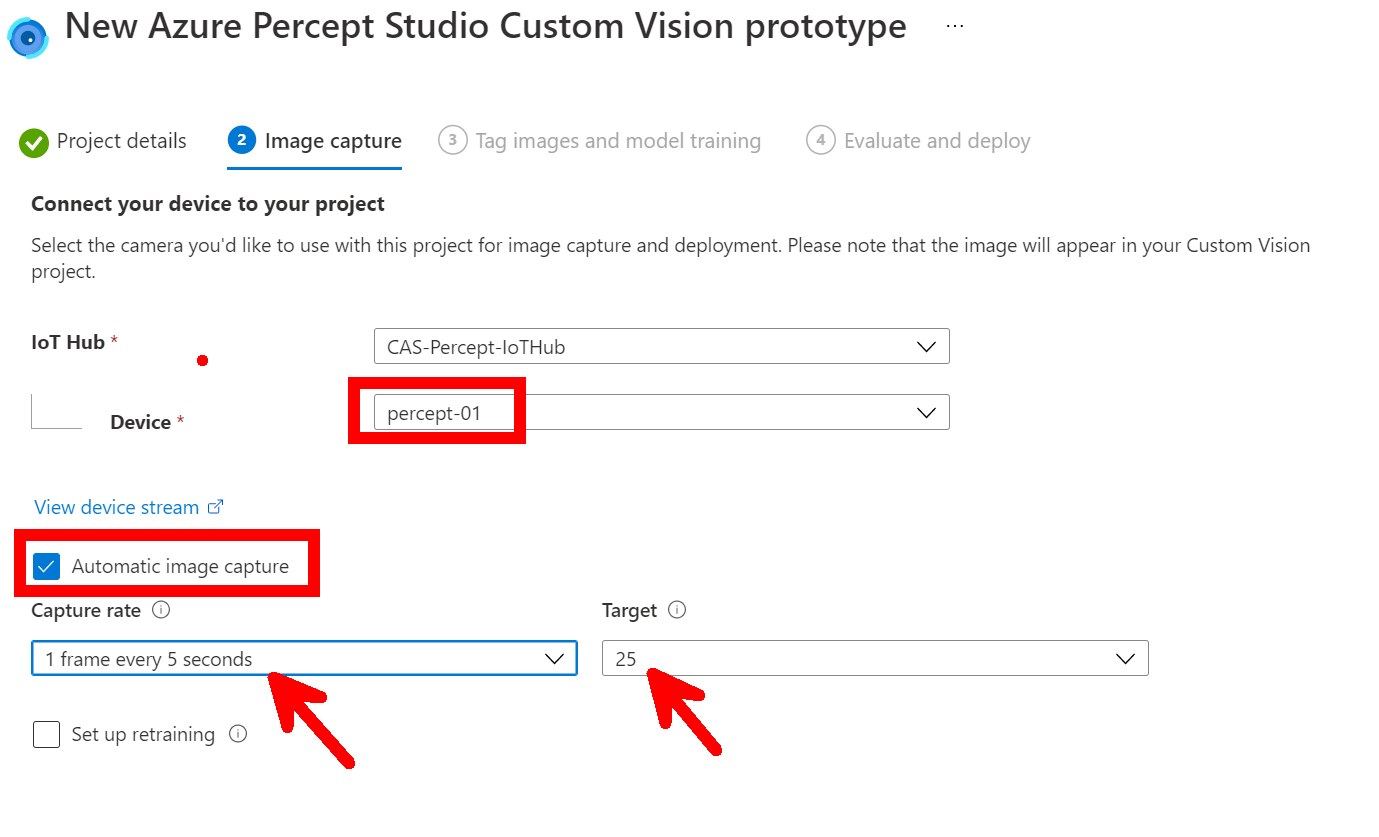
Now if you click the next button you can go to what looks like a pointless page but stick with us there is a reason for this, but click the Open project in custom vision link in the centre of the page, this will open the customer vision project and there will be a few agree boxes to check on the way but then you should have your project open.
As you can see there are 2 projects in my Custom Vision and the left one is the new one we just created with me holding one of the Aircraft Horizontal Stabilizer Ribs which goes on the front of the Horizontal Stabilizer. Click the project to open it and lets look at the images we managed to grab.
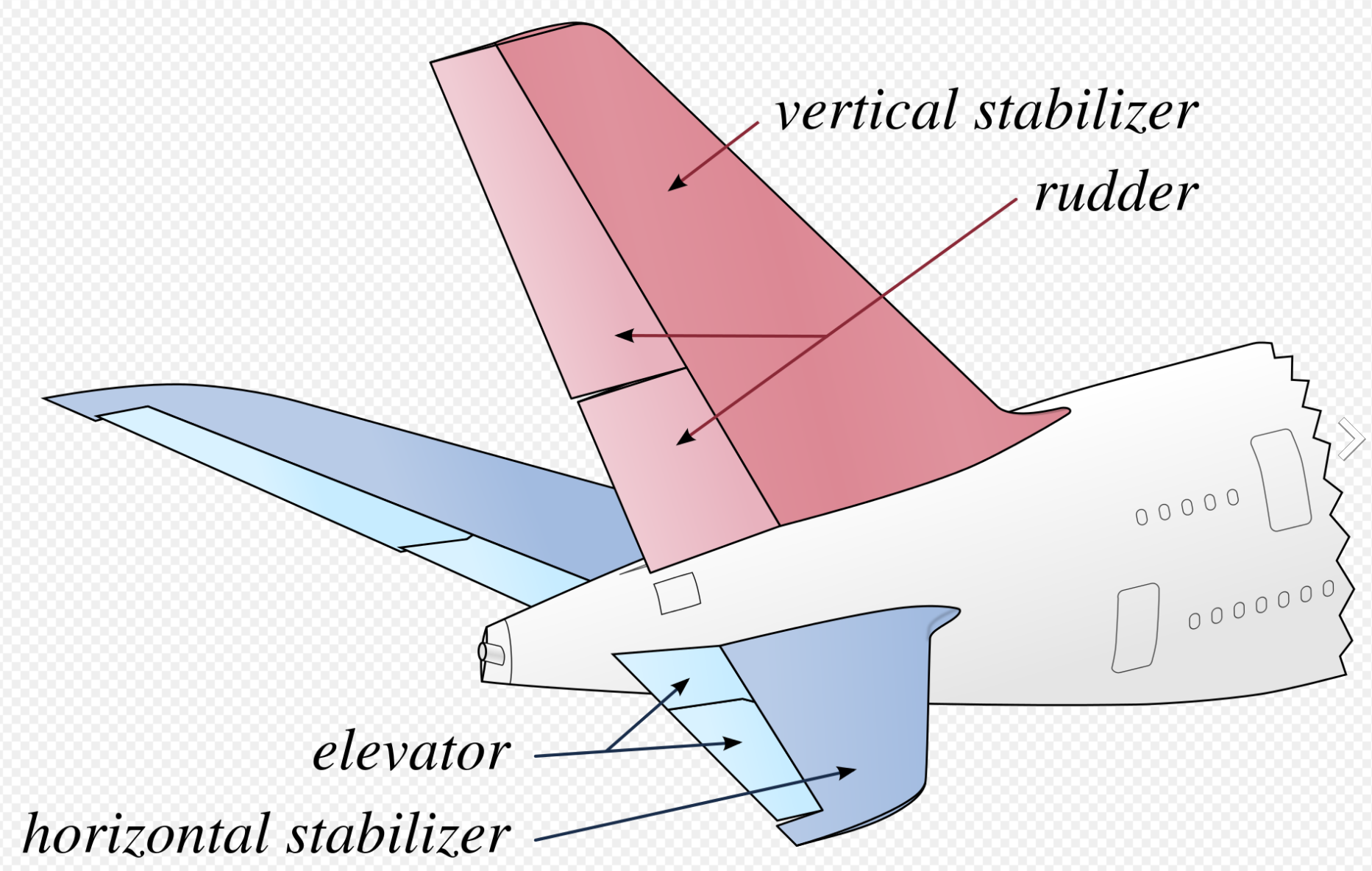 Wiki - Stabilizer (aeronautics)
Wiki - Stabilizer (aeronautics)
Tagging the Images
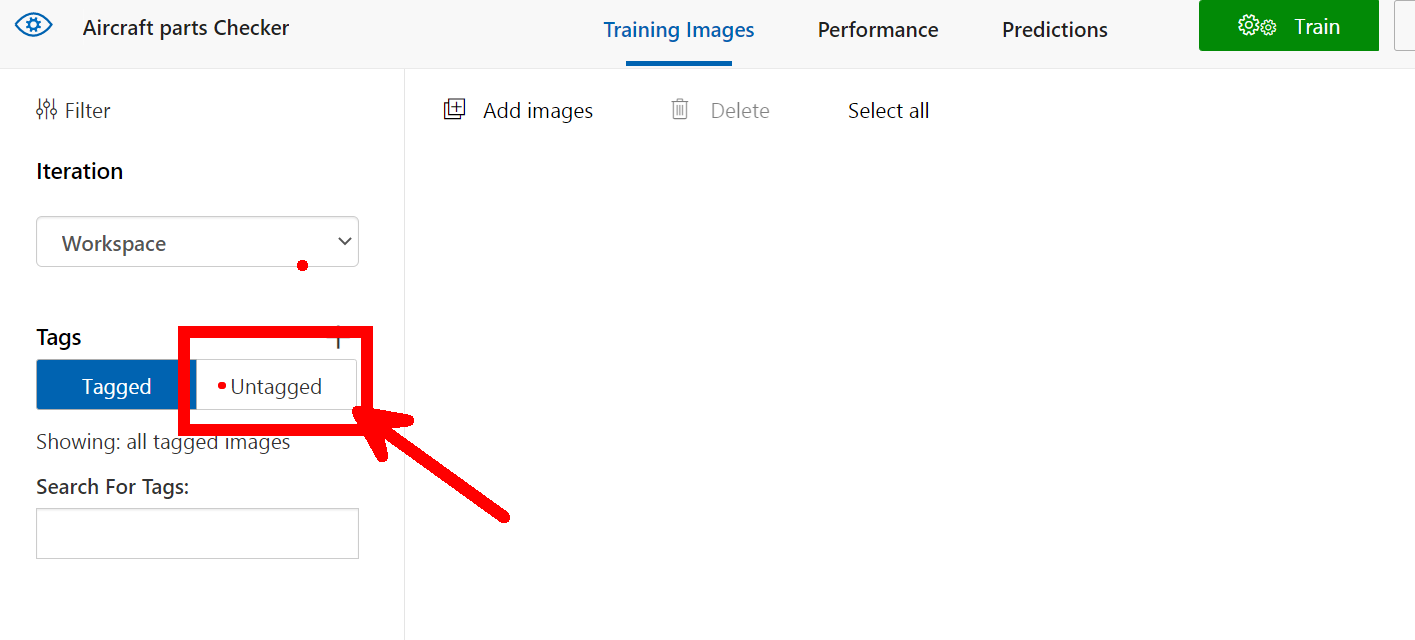
You will look and at first (Like me!) wonder where all those images went but don’t panic they are just Untagged so on the left menu click the Untagged button to view them all.
Clean up the images
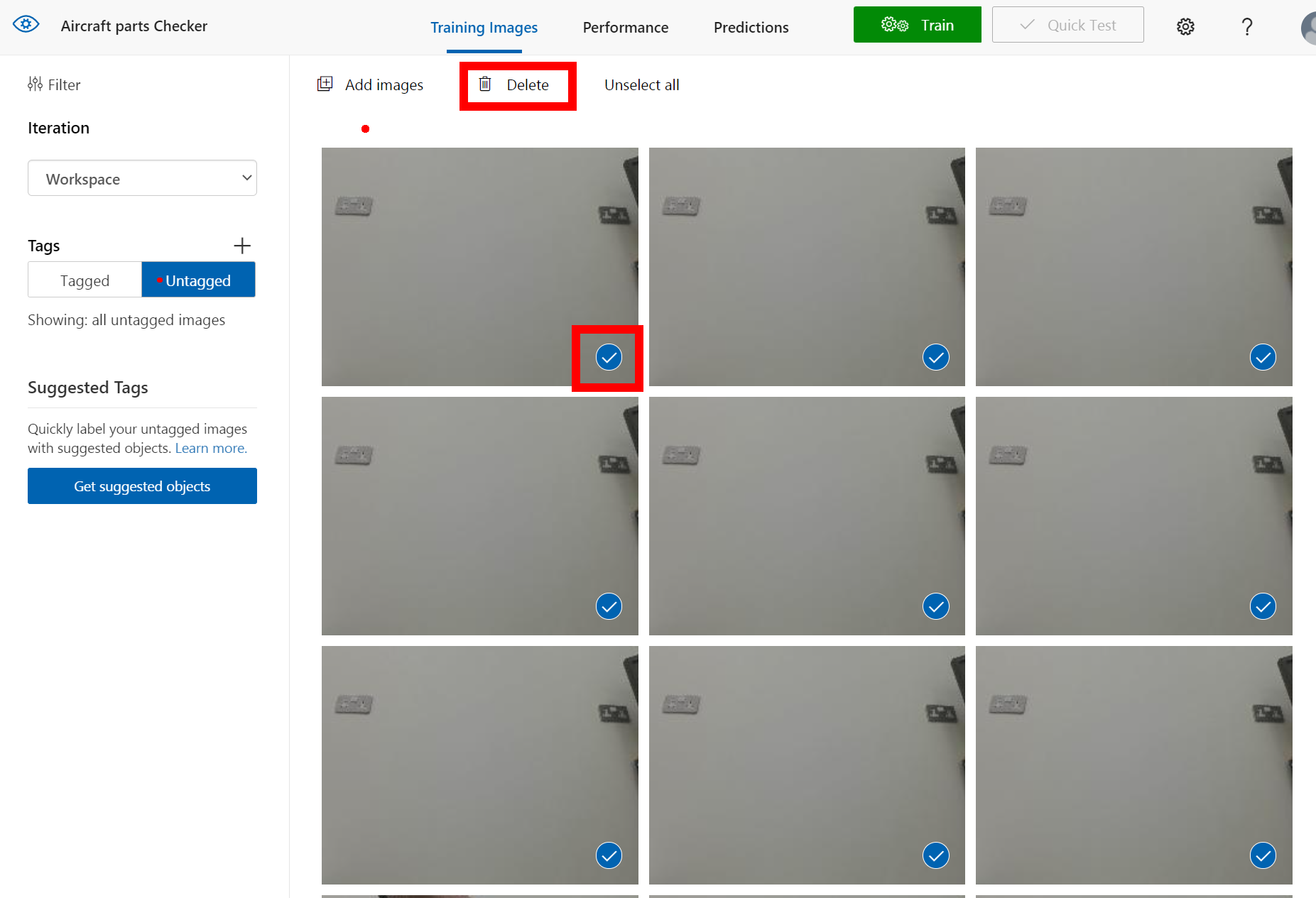
First I like to go through the images and remove all the either poor quality or clearly nothing to see here images, you can do this by hovering over the bottom right of the image, you will see a white tick appear for you to click. Once clicked it turns blue to show it’s selected repeat for all the images you want to remove. Once complete at the top of the page is a Delete button that will delete them all for you.
The next part is sadly rather laborious and boring so I hope you have a fresh cup of IoTea as this can take a while.
So select the image and then using you mouse hover over the part you are interested in within the image and you hopefully should see a bounding box around it to select. Once selected you will see a Text Entry appear so that you can give it a Tag name, this name will be what is shown when the Percept views this part and decides to show the tag name on the screen as part of look what I found bounding box, so pick a good name. As I am tagging aircraft parts I am giving them the Aircraft Component reference from the drawings.
If you don't get a bounding box on the part you want to select just Left mouse click and draw your own box.
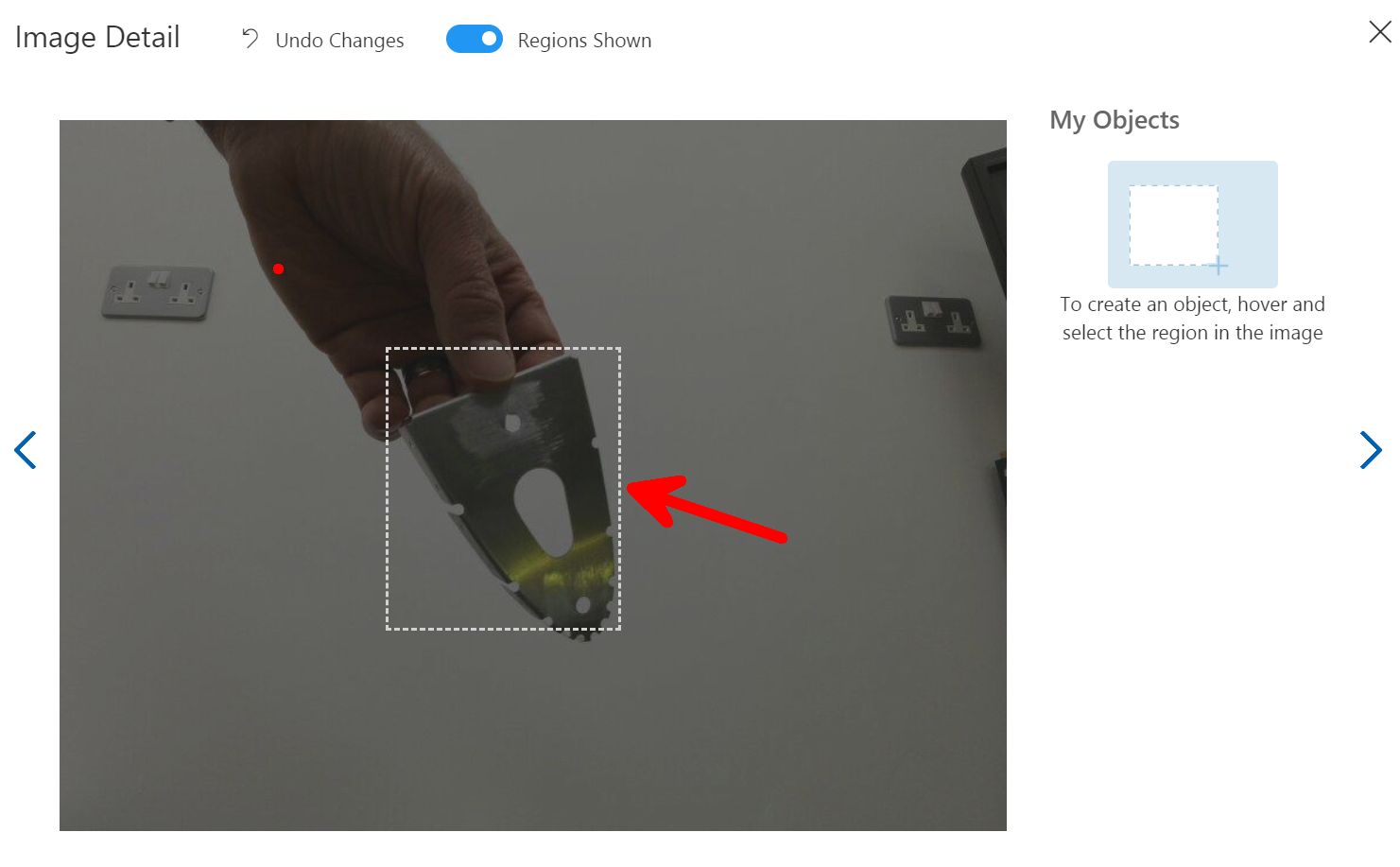
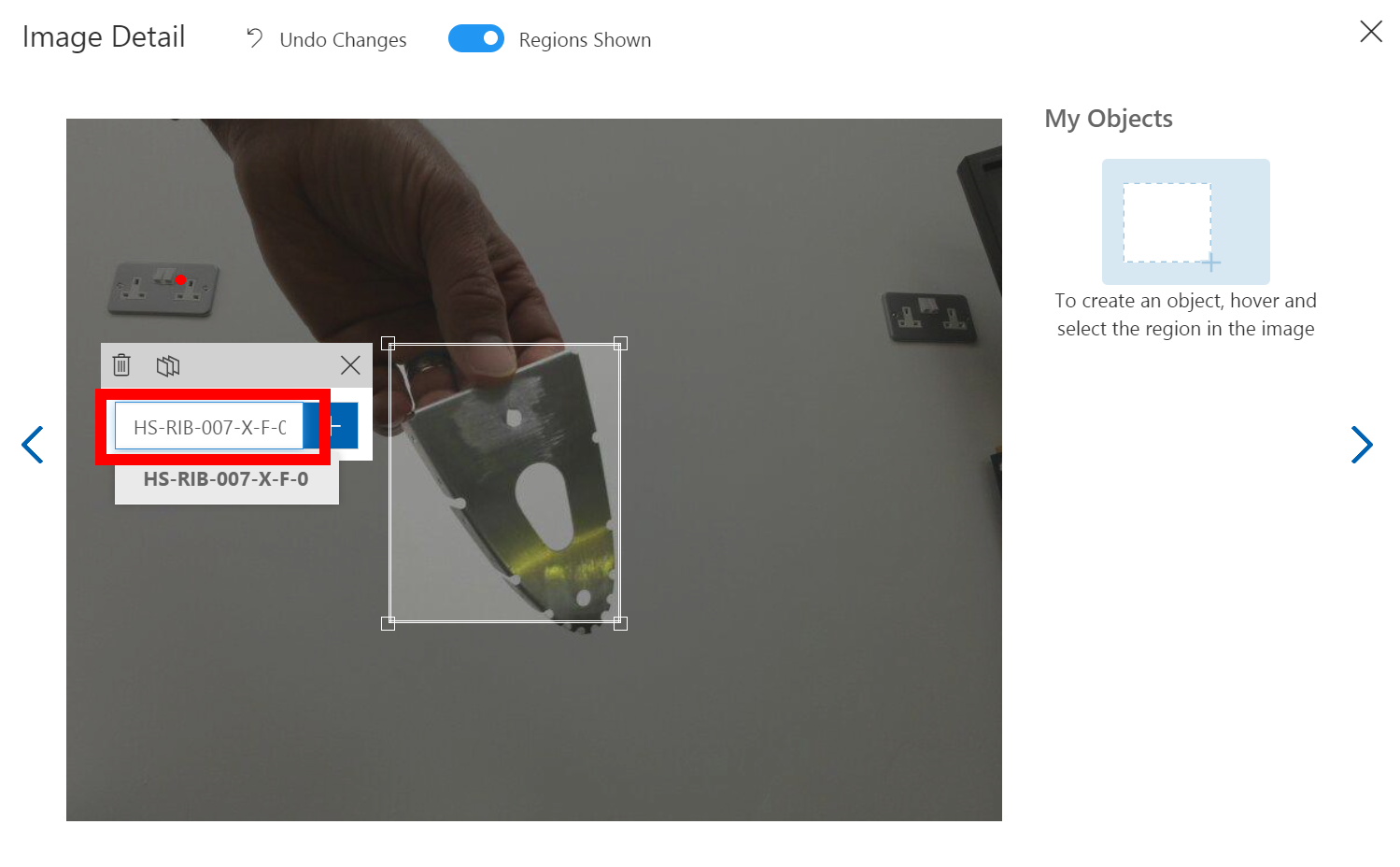
As you move to the next image using the Arrow to the right of the modal box on the screen the next image will appear and it’s just a repeat of the process, however when you select the next area to tag the previous Tag names will appear so it’s quicker to just click along through the images.
When you have tagged all the images click the close X top right, you will see that you now don’t have any untagged images so select the Tagged button so that you can see them all again.
Now this is Imortant
You need a minimum of 15 images for each tag, in my case I only managed to capture 12 so I was a few short, so remember when I said before that the Azure Portal seemed to leave you hanging with that pointless page to select Custom Vision well this is where you need that.
Go back to that browser tab (You didn’t close it did you!) and then you can click the Previous button bottom left and again select another Automatic Image Capture. This seems tedious but it’s the quickest and easiest way I have found to grab all the images in the correct format and sizes etc and upload them into the Custom Vision Project.
SO take another batch of images of that component and repeat the tagging process, 15 is the minimum number need for the training to take place ideally you want 30-40+ of each part/object from many directions in many lighting levels etc…
Training
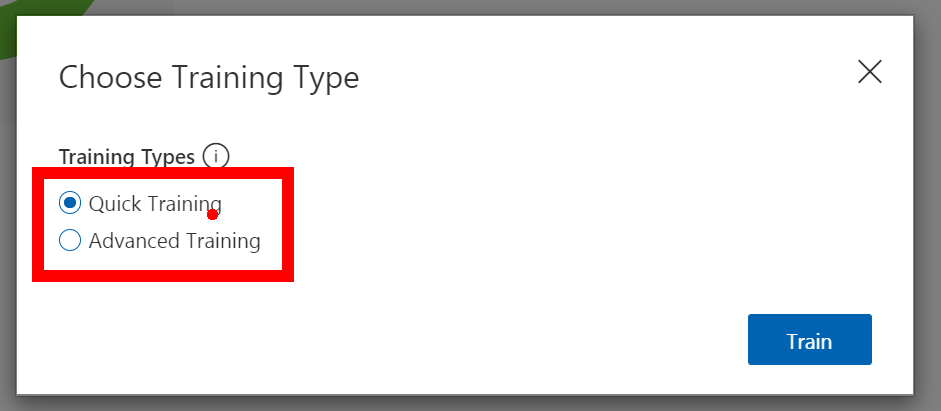
Now you have more than 15 images hopefully closer to if not more than 40 images you can train your model, so there is a nice compelling big green Train button at the top of the screen. Give it a click and you will be asked what type of training I normally always select Quick and then go refresh that Cup as this part takes a few minutes.
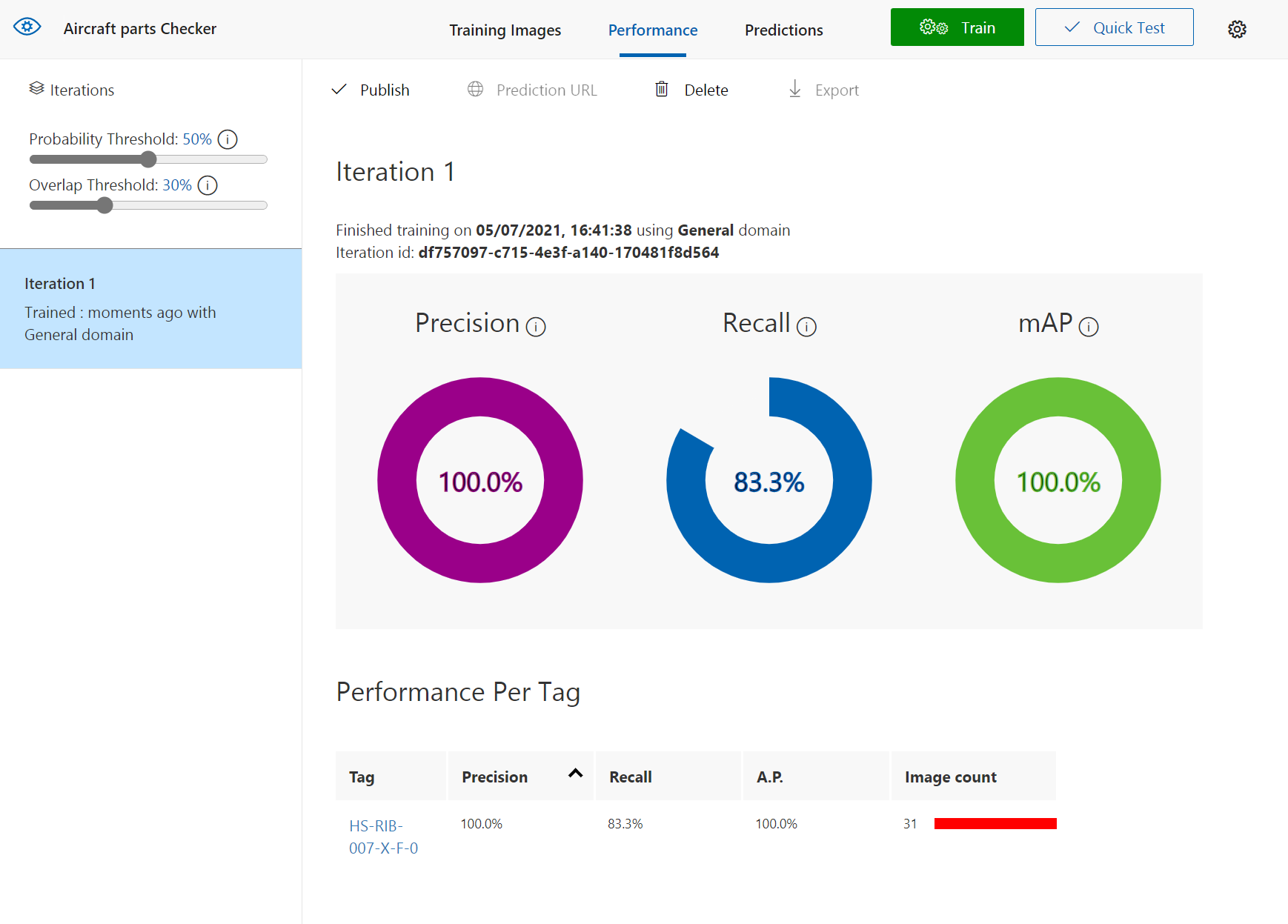
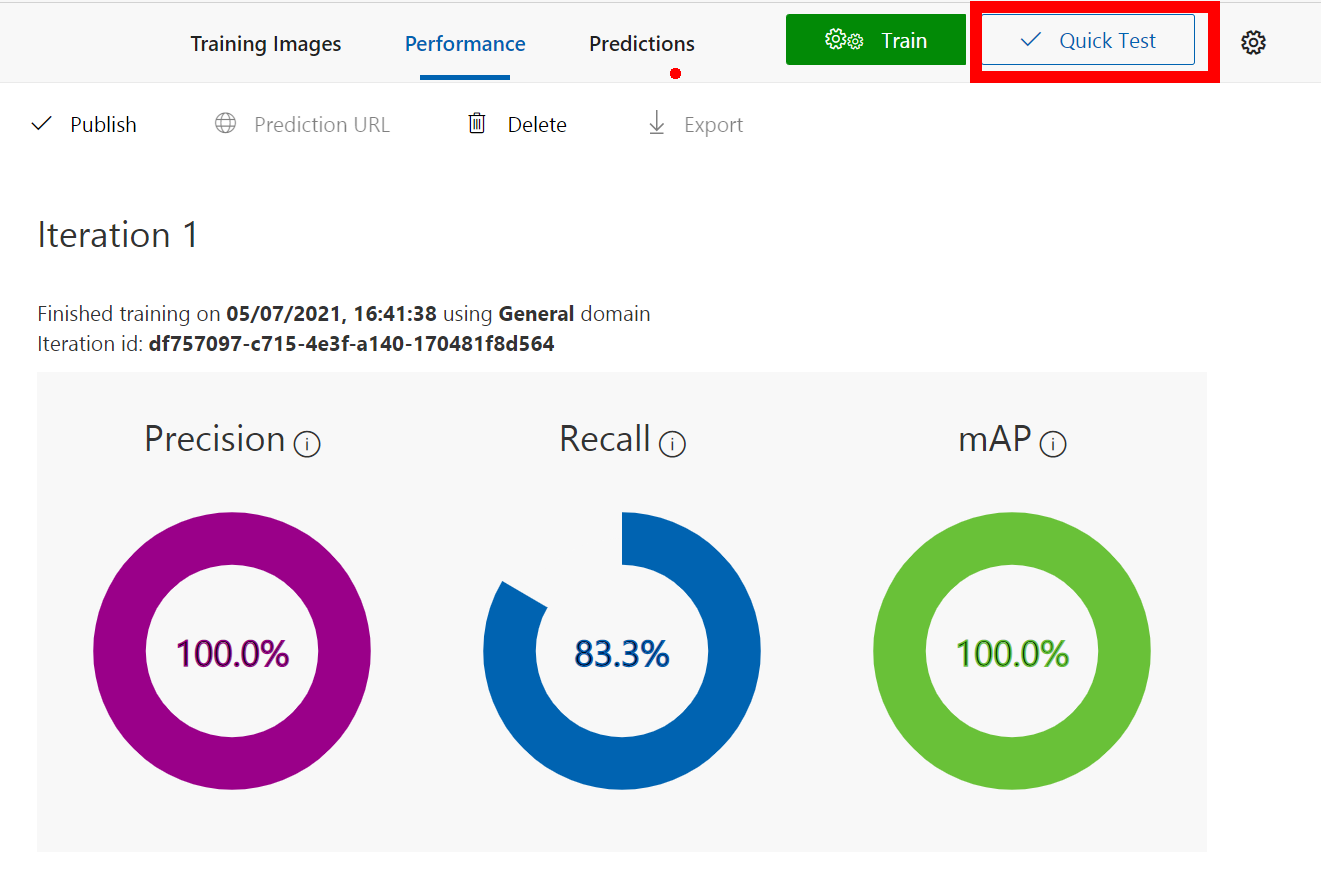
Once it’s trained you should see a nice page with lots of high percentages like below, but don’t be fooled it’s not really 100% accurate but we can test it and see how good it really is.
Testing
Like all good developers we like to test and this is no different, so at the top of the page click the Quick Test button.
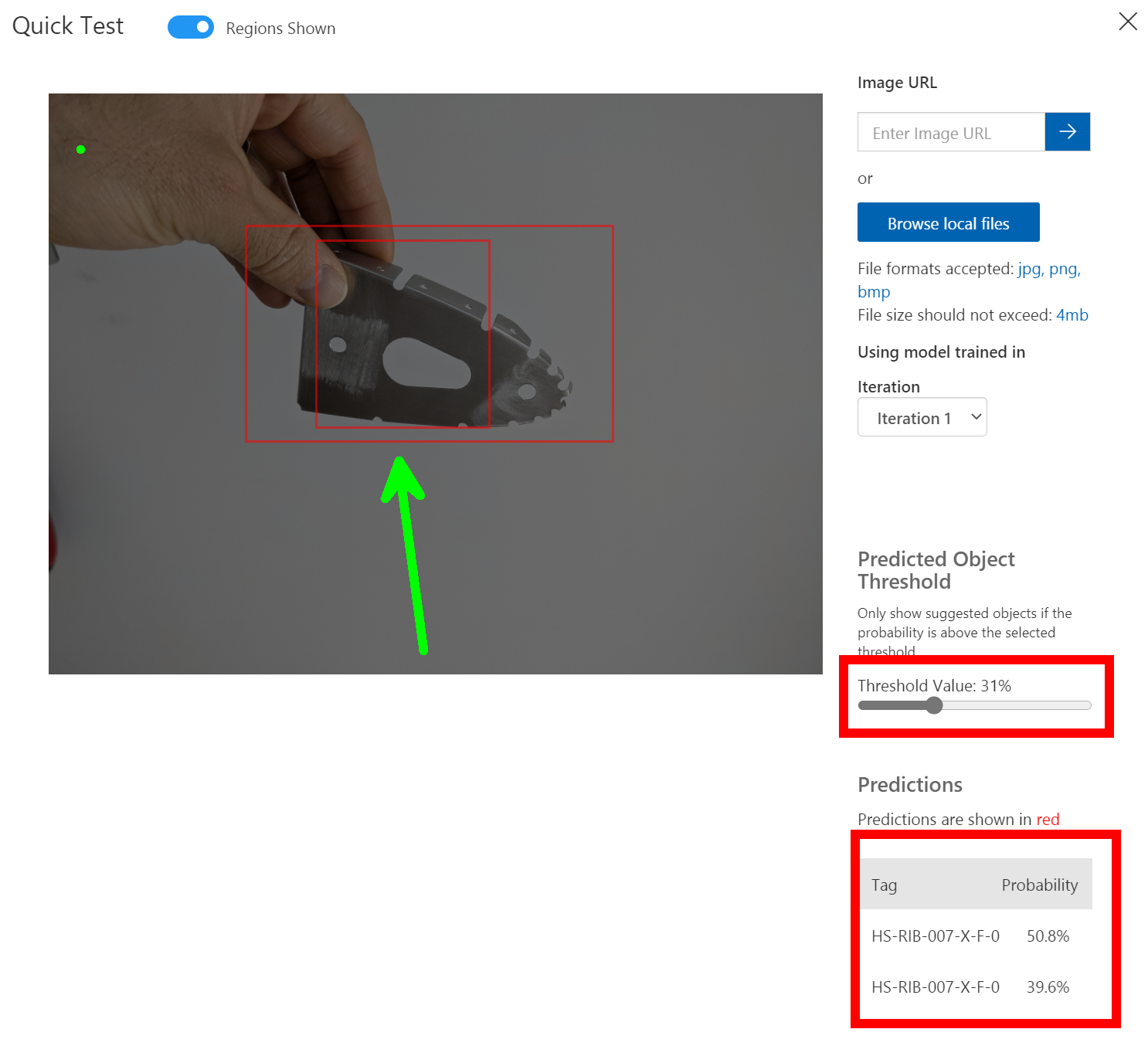
Sadly you do need to grab an image that is not already used so in this case I just use my Mobile phone to take an image and then copy to my PC using the awesome Your Phone feature in Windows or if you still have the browser tab open with the Webstream from the Percept you can do a screen clip from that browser. Only downside is that the bounding boxes from you as a Person may be over the image hence me preferring to using my mobile phone.
As you can see when you give it an image it will show bounding boxes and the prediction rates for those boxes, you can use the slide to change the Threshold value so that you can hide the noise if there is any.
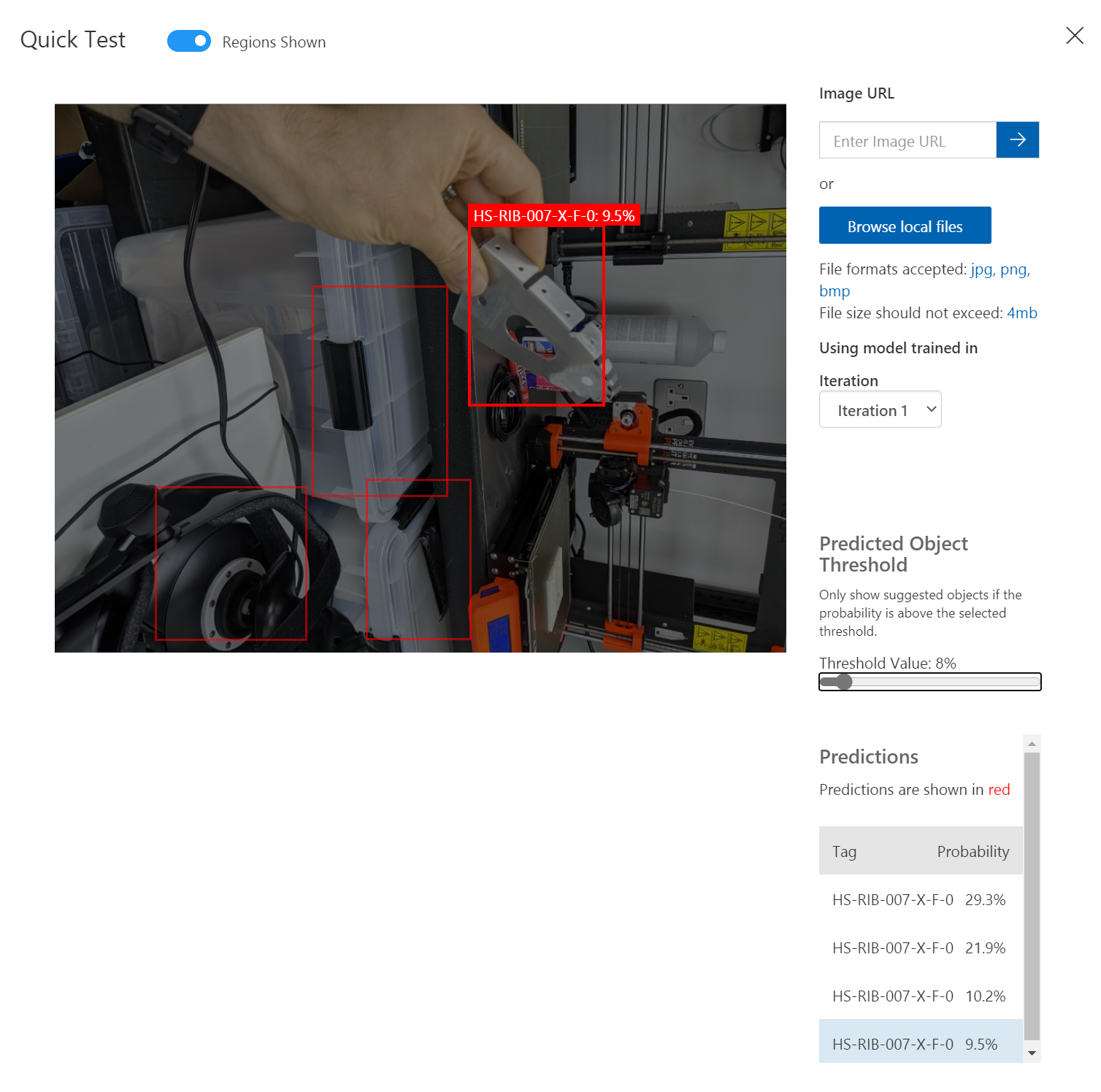
For a 2nd attempt with some noise in the background you can see that I had to move the slider all the way down and it was only 9.5% probability that it could identify the Rib, so this means the test has proven that more images are required and more training.
Iterate and Improve
The process is very simple to set-up and train a customer vision model with the Azure Percept, and as you can see with a component from the aircraft on the very first training run it was fairly good with the white background but poor with all the noise.
So I went on and spent some time training with even more photos and even added in the next RIB along in the build so there were 2 parts similar.
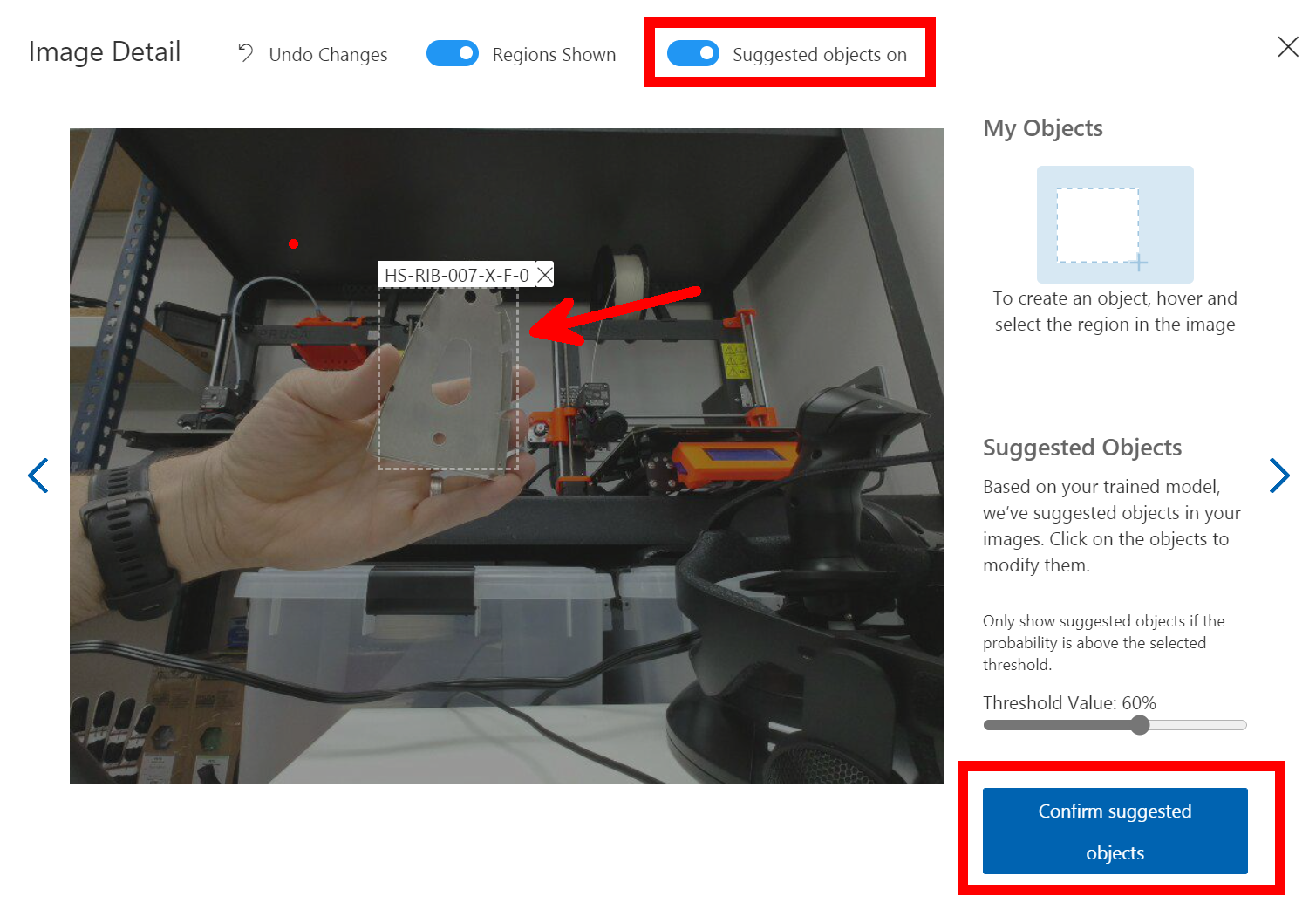
However now that you have a trained model that is improving when you take the images and your tagging them you will see at the top of the Tagging Dialog a slider for Suggested Objects On if you turn this on and give it a second or two it should find your object and bounding box it with a big blue Confirm Suggested Objects button to click. If this doesn’t work repeat the old way of selecting or drawing the bounding box until it has learned enough.
The advantage of using the suggested was is that you can creep the slider up and it’s a form of testing for the images and the Model as well, so you can see it improving over time.
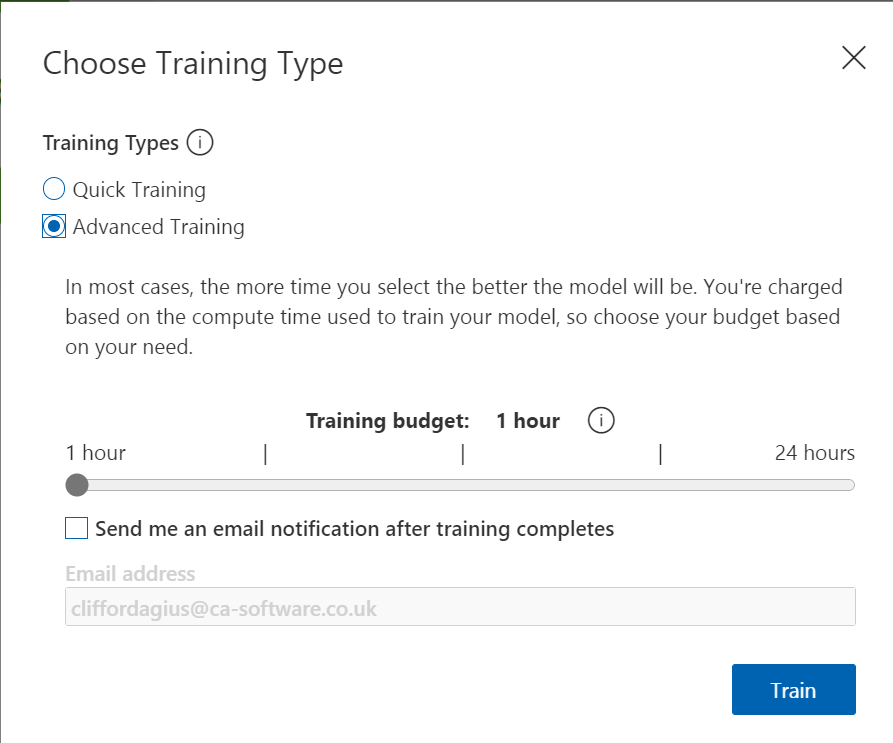
When you have tags a lot more images and you are confident you have a good selection you can improve the trained model by giving it more resources and more time to learn. You do this by selecting Advance Training after clicking the Green train button, this will open the dialog some more and show you a slider where you can allocate the time you wish to train the model for and even have it send you an email when it’s done.
Final step
Now that we have a model that we have Trained, Tested and Iterated with to a point that we feel comfortable sending down to the Edge and using in Production we can go back to the Azure Portal and Percept Studio Page to finish things off.
The last Tab is for Evaluate and Deploy and it’s here that we send the model to the device so that it can be used without the connection to Azure, yes that’s right it can work away at the Edge even with a slow or non-existent connection.
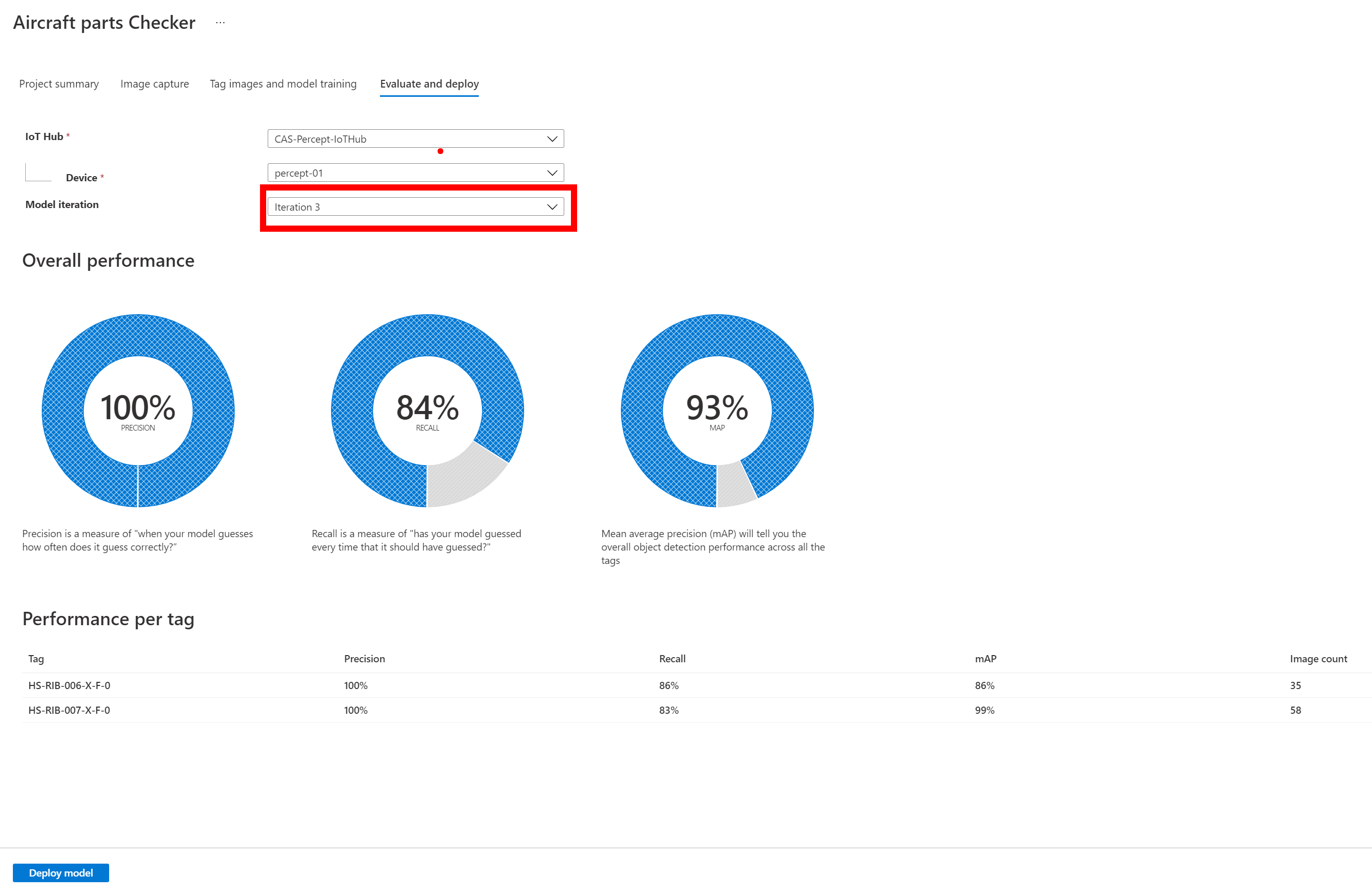
Just select the Device and the Iteration of the Trained model you wish to use and then tap Deploy once that is done you can open the Web stream to the device and you will notice that there will be a message for a minute or two on the first load where it shows Loading Model after this it will show live tagged images when you hold the parts in front of the camera.

Results
You will see that when I am holding a Part in front of the Percept camera it is correctly identifying the part and the last 3 digits are it’s confidence that it’s found the correct part and as you can see with just 35 and 58 images of the two parts I trained it’s already very impressive, but for production you would want more images in different lighting levels etc.


Conclusion
Building this blog and training the models took a few hours but most of that was off doing something else while the training system worked away, if I’m honest I probably only spent maybe an hour actually working on it and have some very impressive results.
Also now you have a trained model it’s not restricted to the Percept devices, you can download the model and use it elsewhere like maybe a Xamarin/MAUI app on a mobile device so that engineers out in the field can have the Parts Checker with them the uses become endless. If you want to read more about this there is a fantastic guest Blog Post by Daniel Hindrikes and Jayme Singleton that’s well worth a look.
I do hope you enjoyed this long walk through all the set-ups to using the Percept Vision system and enjoy playing with you Vision Models, if you have any questions just reach out on Twitter or LinkedIn.
Happy Coding, I’m off back to building the Sling.
Cliff.